오랜만에 글을 올리는데 맘처럼 쉽지가 않네...
어쨋든 오늘 하려는 건 스크래핑인데 예전과는 다르게
어떤 홈페이지를 보면 url이 다 같은 경우가 있다 어디를 들어가도 뒤에 쿼리스트링이 붙지 않는
예를 들어
https://www.courtauction.go.kr/ 법원경매정보 사이트같은
여기의 물건의 값들을 스크래핑을 해볼 것이다.
먼저 저 사이트에 접속해

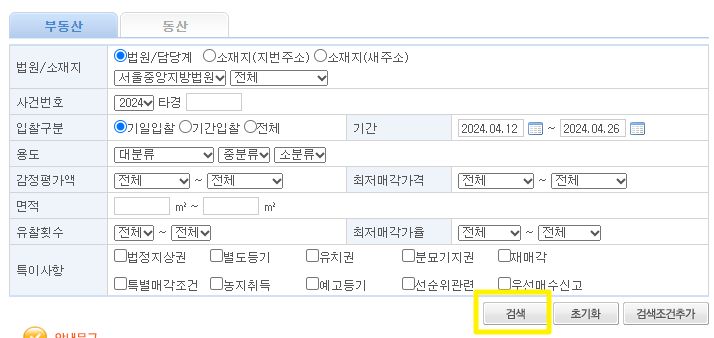
검색을 해 보자 원하는게 있으면 값들을 넣으면 될 껀데 필요한게 없기도 하고 귀찮아서 나는 디폴트 값으로 하겠다

이런 검색 결과가 나오는데 여기서 개발자 도구(F12)를 키고 물건의 정보가 들어 있는 파일을 찾는다

여기 사이트의 경우는
RetrieveRealEstMulDetailList.laf 이 파일인 것 같다
network에서 저 파일을 선택하고 response창을 누르면

물건의 정보가 나오는데 여기서도 저번과 같이 형태를 기억하자
table이고 class="Ltbl_list"이다
그리고 밑을 내려보면 값들이 나오는데 가격을 들고 오려고 하니까
<td class="txtright">의 안에 가격들이 있다 기억하자
이제 url이 없는 상태로 저 정보를 긁어 와야하는데 그럴때

curl로 복사를 하자
curl은 client url 로 url로 할 수 있는 것들은 다 할 수 있다고 나와있다
그리고 복사한 curl을
Convert curl commands to code
GitHub is matching all contributions to this project on GitHub Sponsors. Contribute Now
curlconverter.com
사이트에 들어가서 python으로 변환하자

이러한 헤더값이나 쿠키값들이 있는 정보가 python으로 변환돼 나온다
이 값을 복사하고 vscode로 가자
import requests
import csv
import requests
from bs4 import BeautifulSoup
#https://curlconverter.com/ 참조
import requests
cookies = {
'WMONID': 'QxhiKu445nz',
'JSESSIONID': 'LQpVtfvcdqHpCqF2uPXze0pVKrKlNXocgW9M22RjjiECVyyFzh3YLAly4ibXWnMQ.amV1c19kb21haW4vYWlzMg==',
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'ko,en;q=0.9,en-US;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
# 'Cookie': 'WMONID=QxhiKu445nz; JSESSIONID=LQpVtfvcdqHpCqF2uPXze0pVKrKlNXocgW9M22RjjiECVyyFzh3YLAly4ibXWnMQ.amV1c19kb21haW4vYWlzMg==',
'Origin': 'https://www.courtauction.go.kr',
'Referer': 'https://www.courtauction.go.kr/InitMulSrch.laf',
'Sec-Fetch-Dest': 'frame',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0',
'sec-ch-ua': '"Microsoft Edge";v="123", "Not:A-Brand";v="8", "Chromium";v="123"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
data = 'bubwLocGubun=1&jiwonNm=%BC%AD%BF%EF%C1%DF%BE%D3%C1%F6%B9%E6%B9%FD%BF%F8&jpDeptCd=000000&daepyoSidoCd=&daepyoSiguCd=&daepyoDongCd=¬ifyLoc=on&rd1Cd=&rd2Cd=&realVowel=35207_45207&rd3Rd4Cd=¬ifyRealRoad=on&saYear=2024&saSer=&ipchalGbncd=000331&termStartDt=2024.04.12&termEndDt=2024.04.26&lclsUtilCd=&mclsUtilCd=&sclsUtilCd=&gamEvalAmtGuganMin=&gamEvalAmtGuganMax=¬ifyMinMgakPrcMin=¬ifyMinMgakPrcMax=&areaGuganMin=&areaGuganMax=&yuchalCntGuganMin=&yuchalCntGuganMax=¬ifyMinMgakPrcRateMin=¬ifyMinMgakPrcRateMax=&srchJogKindcd=&mvRealGbncd=00031R&srnID=PNO102001&_NAVI_CMD=&_NAVI_SRNID=&_SRCH_SRNID=PNO102001&_CUR_CMD=InitMulSrch.laf&_CUR_SRNID=PNO102001&_NEXT_CMD=RetrieveRealEstMulDetailList.laf&_NEXT_SRNID=PNO102002&_PRE_SRNID=&_LOGOUT_CHK=&_FORM_YN=Y'
response = requests.post(
'https://www.courtauction.go.kr/RetrieveRealEstMulDetailList.laf',
cookies=cookies,
headers=headers,
data=data,
)
# 엑셀 파일로 저장하기
filename = "법원경매.csv"
f = open(filename, "w", encoding="utf-8-sig", newline="")
writer = csv.writer(f)
columns_name = ["순서", "가격"] # 컬럼 속성명 만들기
writer.writerow(columns_name)
# soup 객체 만들기
soup = BeautifulSoup(response.text, "lxml")
costbox = soup.find('table', attrs={"class": "Ltbl_list"})
costs = costbox.find_all('td', attrs={"class": "txtright"})
i = 1
for cost in costs:
price = cost.text
print(f"{str(i)}위: {price}")
data = [str(i), price]
writer.writerow(data)
i += 1
형태는 저번 음원차트랑 비슷하다 soup객체 만들기에서 table과 class명 그런것들이 달라진 것이고
음원차트 경우는 url을 요청해서 soup에 담았다면 이번에는 변환한 값들을 response에 담고 그것을 text로 만들어 soup에 담는게 변환 된 정도이다.
아직 공부하는 단계라서 허접하지만 더 열심히 공부를 해 봐야겠다.
읽어주셔서 감사도링~
'개발 > python' 카테고리의 다른 글
| Django (0) | 2024.04.25 |
|---|---|
| flask riot api (1) | 2024.04.19 |
| Flask (0) | 2024.04.17 |
| scraping (3) | 2024.03.12 |
| python 입문기 (0) | 2024.03.12 |



